Page History
the , they The idea behind this change is to allow its very Now all so we ; so the
What's next?
| Children Display |
|---|
have to the document document start creating go to Creating Connectors From
The following diagram illustrates how the Connector Framework interacts with the connector implementation in order to run a crawl:
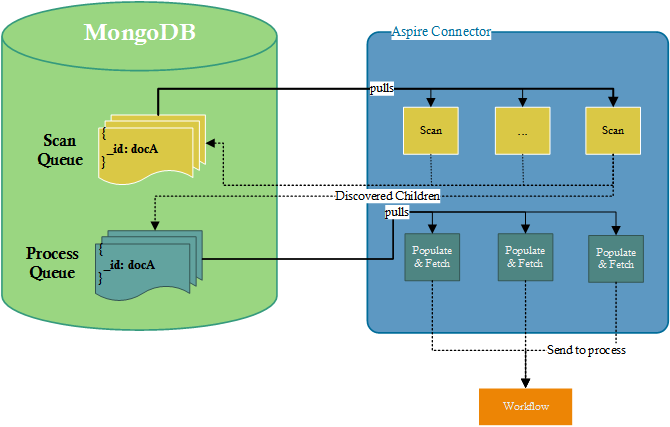
Overview
Content Tools