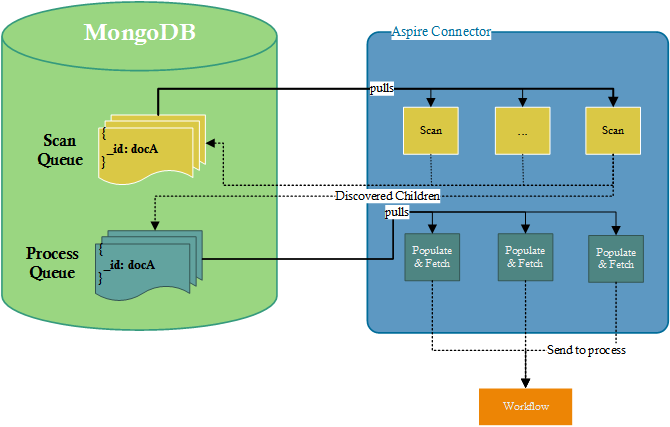
The biggest change in Aspire 3.2 is related to the way connectors work. They now use an external database (MongoDB) to hold all of the crawling informationsuch as document urls, status, statistics, snapshots (for incrementals), logs, etc. This allows the connectors to work distributed from the architectural design.
All of the connectors run under the same principles, using the same logic, so that each connector is more like a Repository Access Provider. We keep them as simple as possible, rather than a complex (multi-threaded) crawling application. The complexity of distributed crawling and multi-threading relies on the Connector Framework.
What's next?
Children Display
all
true
Responsibilities that the Connector developers implement:
Scan
the
the repository document containers to discover new documents to process
Populate
document
document metadata
Fetch
document
document content
If you want to create your connector right away, go