Overview
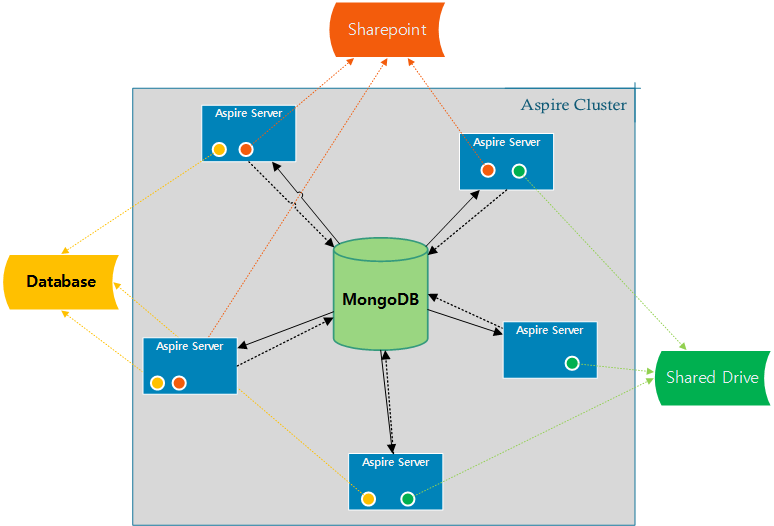
Since the 3.2 release, Aspire connectors are able to crawl in distributed mode automatically. Since all the crawl control data is stored in MongoDB, by just adding more Aspire servers configured to use the same MongoDB, the common connectors are going to crawl distributively.
Each connector is responsible for talking to the repositories, scanning through all the items to fetch and store its IDs to MongoDB for being processed later by any other server or itself.
Configuration
In order to setup an Aspire Cluster for Distributed Processing, you need to do the following steps:
Setup MongoDB
You need to configure all Aspire servers to use the same MongoDB Installation, configure all the Aspire Servers config/settings.xml file
MongoDB Settings<!-- noSql database provider for the 3.2 connector framework --> <noSQLConnectionProvider sslEnabled="false" sslInvalidHostNameAllowed="false"> <implementation>com.searchtechnologies.aspire:aspire-mongodb-provider</implementation> <servers>mongodb-host:27017</servers> </noSQLConnecitonProvider>
If you need to connect to a multi node MongoDB installation, check: Connect to a Multi-node MongoDB InstallationSetup Zookeeper
More details for Zookeeper installation and settings at Failover Settings (Zookeeper)
Failover Settings (Zookeeper)For each Aspire Server make the following change to the <configAdministration> section of the settings.xml file<zookeeper enabled="false" libraryFolder="config/workflow-libraries" root="/aspire" updatesEnabled="false">
to
<zookeeper enabled="true" libraryFolder="config/workflow-libraries" root="/aspire" updatesEnabled="true">
Uncomment the line with:
<!-- <externalServer>127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2181</externalServer> -->
And write the zookeeper server that you have installed as follows:
<externalServer> host:port </externalServer>
If you are using a cluster of zookeeper servers separate each server with a comma:
<externalServer> host1:port1, host2:port2, host3:port3, ... </externalServer>
By default if no external server is specified, Aspire will start an embedded ZooKeeper server on the port specified in the <clientPort> tag, and it will not be connected to any other ZooKeeper. This is the default for non-failover installations.
Install the content sources to distribute
Now it is time to think about which content sources you want to crawl distributively, and from what Aspire Servers, according to your solution architecture.
For this, configure the content sources in one of the servers and once you have them correctly configured export the content source and import it into the Aspire Servers you want to crawl this content source in parallel.
Crawl Control
Controlling distributed processing is very simple. Simply log in to any Aspire node in the cluster and perform the required action (start, pause, resume or stop). All Aspire nodes in the cluster will then move to the same state.
If you need to shutdown one (or all) servers, you must first pause all running crawls. If you DO NOT pause the crawl and shutdown Aspire on a node in the cluster, Aspire will pause all running crawls before shutting down
Adding or Removing Nodes on the Aspire Cluster
If you need to add Aspire nodes to the Aspire cluster, simply start an Aspire instance that uses the same Zookeeper and MongoDB instance. As Aspire starts, it will copy the current configuration from the cluster and begin processing (if crawls are currently in process).
If you need to remove an Aspire node from the cluster, either pause all running crawls or allow all them to finish. Once no crawls are active, simply stop Aspire on the desired servers (and turn them off if required). Once only the desired Aspire nodes are running, login to the user interface on any Aspire node and start or un-pause crawls as required
If you need to remove one (or all) Aspire nodes from the cluster, you must first pause all running crawls. If you DO NOT pause the crawl and shutdown Aspire on a node in the cluster, Aspire will pause all running crawls before shutting down
Overview
Content Tools