Step 1. Launch Aspire and Open the Content Source Management Page
- Launch Aspire (if it's not already running).
- Go to Launch Control.
- Browse to: http://localhost:50505
For details on using the Aspire Content Source Management page, see Admin UI.
Step 2. Select or Add a Content Source
Select a "Content Source" to work with.
- From Content Source, click Add Source to add a new content source or select and existing one.
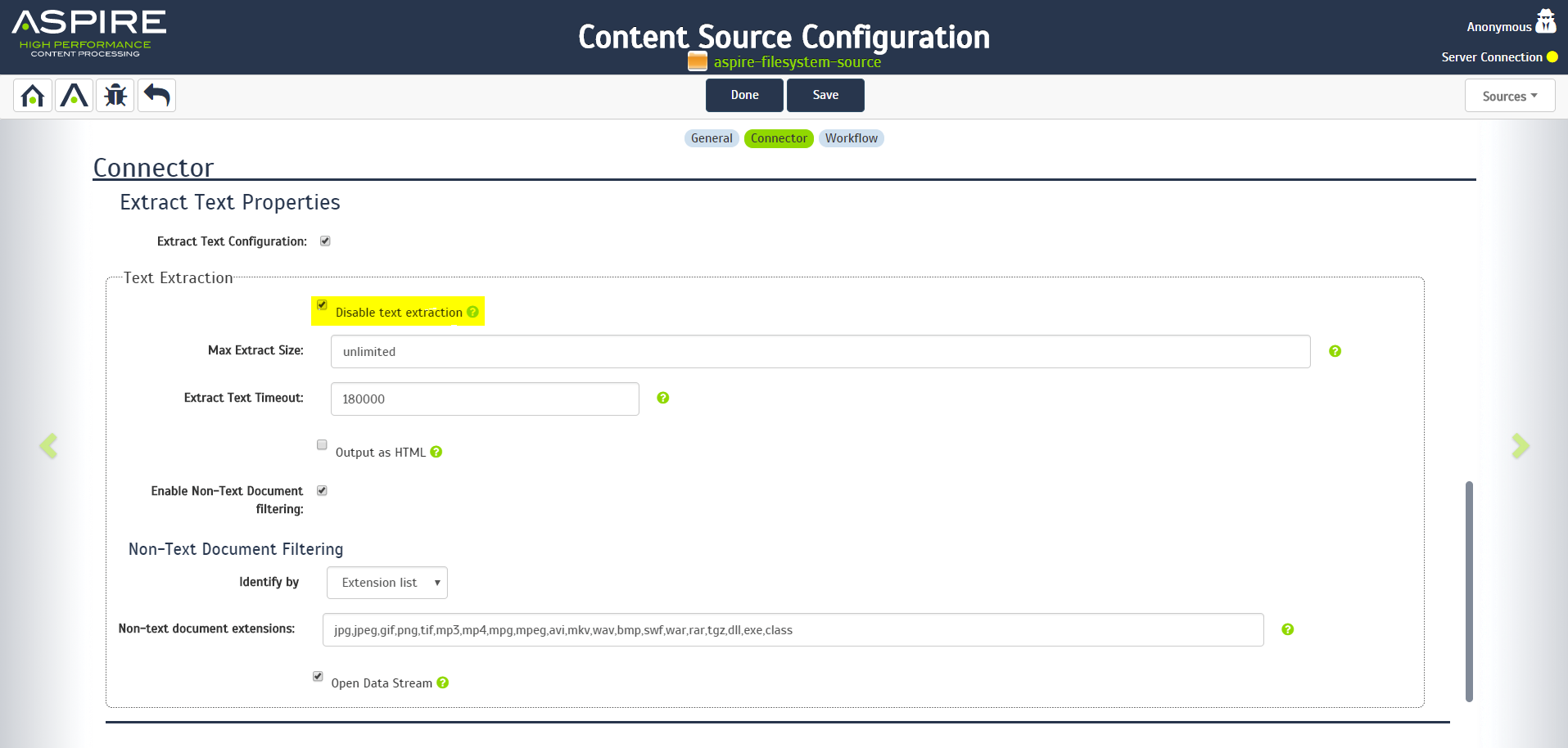
Step 2a. Disable Text Extraction
In the "Connector" tab:
- Locate the "Extract Text Properties" section
- Check "Extract Text Configuration"
- To show the configuration parameters
- Check "Disable text extraction"
- To disable the text extraction
- Check "Extract Text Configuration"
If you need text extraction, you will need to add a text extraction stage in to the work flow later
Step 2b. Configure Workflow Information
In the Workflow tab:
install the binary writer either by dragging it from the Applications section of the workflow configuration or by adding a custom application with the group id “com.searchtechnologies.aspire” and the artifact id “app-hdfs-binary writer”
Configure the parameters
- HDFS Base
- The base directory on the hdfs file system under which all content will be written
- Form
- hdfs://<server>:<port>/<path>
- Example
- Get content source from document
- When checked, the content source name with be automatically extracted from the Aspire document. The field holding the value can be configured below
- Content source field
- The field in the Aspire document in which the content source name is held, used when getting the content source from the document
- Form
- /path/to/field
- Example
- /doc/sourceId
- Content source
- The static value of content source name to use when not getting the content source from the document
- Form
- name
- Example
- myContentSource
- Use default ID field
- By default, the id field is taken from the fetchUrl field. If you want to use a different field, uncheck this box.
- Id field
- When not using the default field for the document id, enter the field that contains the document id here.
- Form
- /path/to/field
- Example
- /doc/fetchUrl
- Hash bits
- The number of bits of the hash to use for the HDFS directory name. The filename is constructed using the MD5 hash of the document ID and the original filename. The file is then stored in a directory whose name is the least significant n bits of the hash, where n is the number of bits given here.
- Form
- <number>
- Example
- 16
- Directory bits
- The number of bits of the hash to use for the grouping the directories.
- Form
- <number>
- Example
- 8
- Suppress deletes
- Checking this box will prevent binary files being deleted when a delete action is encountered. Instead a “marker file” will be left to indicate the binary was deleted
- HDFS Options
- Security
- Choose the type of security to use to access the HDFS file system- Kerberos or none
- User principle
- The principal user for Kerberos
- Key tab file
- The user's key tab file
- Form
- File path
- Example
- config/myUser.keytab
- Add resources
- Check this box if you need to add Hadoop resources to the configuration (such as site-core.xml)
- Resource file
- The path to a resource file to add to the configuration
- Form
- /path/to/file
- Example
- config/core-site.xml
- Block size
- The size of block to be used when accessing the HDFS file system
- Form
- <number> <unit>
- Example
- 32mb
- Buffer size
- The size of buffer to be used when accessing the HDFS file system
- Form
- <number> <unit>
- Example
- 32kb
- Replication
- The HDFS replication factor
- Form
- <number>
- Example
- 3
- Security
- Debug
- Check this box to enable debug messages




Step 3: Initiate a Crawl
Now that the HDFS writer is set up, a crawl can be initiated.
- When crawling the content will be written to HDFS
Overview
Content Tools