FAQs
General
Why does an incremental crawl last as long as a full crawl?
Some connectors perform incremental crawls based on snapshot entries, which are meant to match the exact documents that have been indexed by the connector to the search engine. On an incremental crawl, the connector fully crawls the repository the same way as a full crawl, but it only indexes the modified, new or deleted documents during that crawl.
For a discussion on crawling, see Full & Incremental Crawls.
Save your content source before creating or editing another one
Failing to save a content source before creating or editing another content source can result in an error.
ERROR [aspire]: Exception received attempting to get execute component command com.searchtechnologies.aspire.services.AspireException: Unable to find content source
Save the initial content source before creating or working on another.
My connector keeps the same status "Running" and is not doing anything
After a crawl has finished, the connector status may not be updated correctly.
To confirm this, do the following:
1. In RoboMongo, go to your connector database (like: aspire-nameOfYourConnector).
2. Open the "Status" collection and perform the following query:
db.getCollection('status').find({}).limit(1).sort({$natural:-1})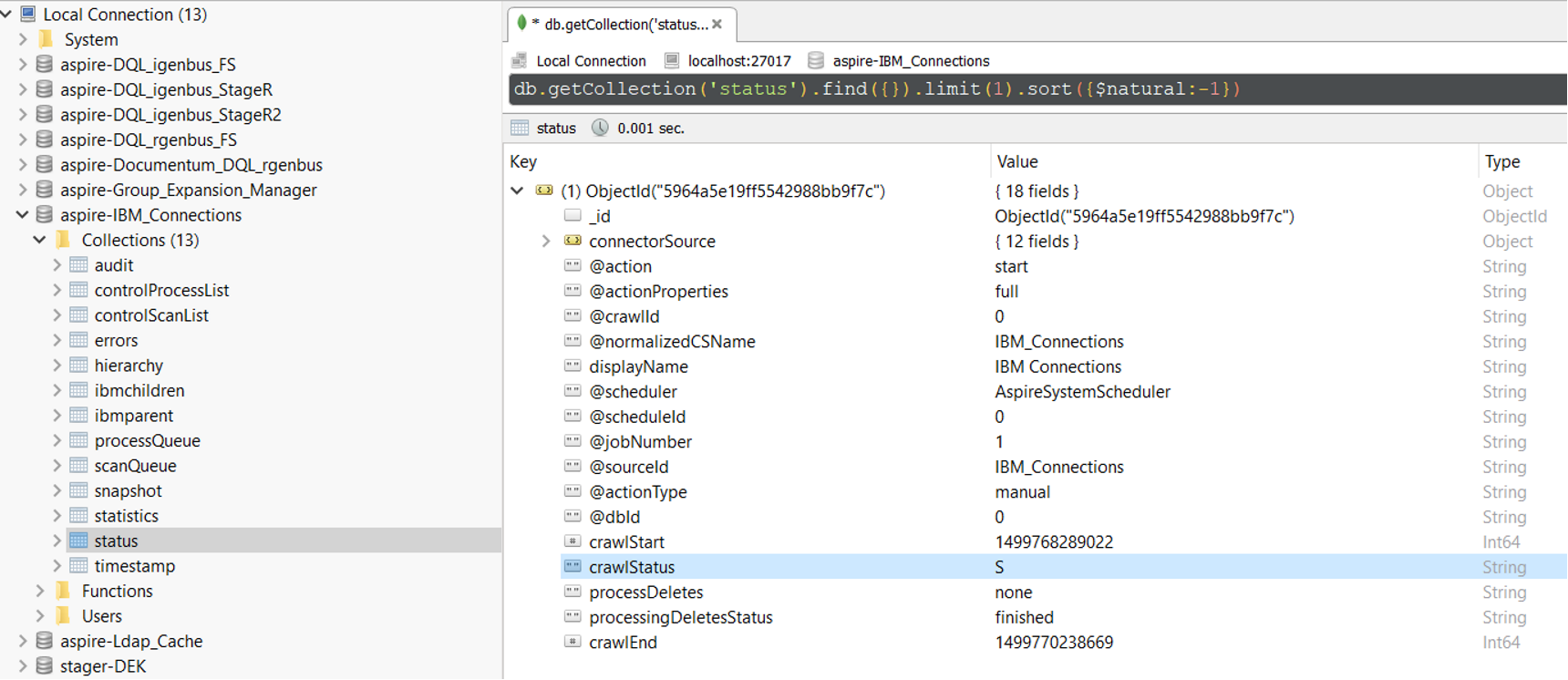
3, Edit the entry and set the status to "S" (Completed).

Note: To see the full options of "Status" values, see MongoDB Collection Status.
My connector is not providing group expansion results
Make sure your connector has a manual scheduler configured for Group Expansion.

1, Go to the Aspire debug console, and look for the respective scheduler (in the fourth table: Aspire Application Scheduler).
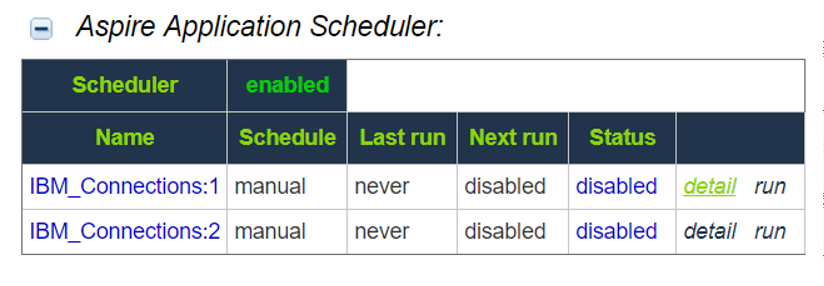
2. If you are unsure which scheduler is for Group Expansion, you can check the Schedule Detail.
- You can identify it with the value: cacheGroups

3.To run the Group Expansion process, click Run.

How does the Activity incremental work?
The Activity incremental is the new way to do low impact incremental crawls in big communities. Activity incremental uses the Activity API in order to retrieve the latest updates from the community - these updates are visible in the Homepage activity section of the JIVE community. By default the Activities will only show the most important and public activities of the community. You can change this by following groups and users with the crawler user; this way more activities from that user or group will appear in the activities section and they will be crawled.
What is an Activity?
Please view the following page: Jive Activity
Why does the normal incremental run when Activity incremental is set?
Activity incremental does not replace the normal incremental, it is just a low impact crawl to fetch the most important updates (activities) from the community. When you set Activity incremental you must set an Activity Count. This count indicates how many Activity incrementals will be executed before a normal incremental is executed. After the normal incremental has executed, the connector will execute the number of Activity incremental crawls specified in the Activity Count again before executing a normal incremental again.
Why doesn't Activity incremental crawl deleted documents?
The Activity incremental only crawls Activities - Activities are only created upon creation or modification of documents.
How do I add more activities from a specific place or user?
You can get more activities from specific places or users by clicking the Follow button in the place or user profile.
What's the difference between Document Level Security and Security Groups?
Document Level Security is the access and visibility you specify when creating a document or a group in the JIVE Community, in documents, files, polls and other type of content this can be if the content is public, if it is only visible for certain members of a group or if only just a few users have access to it.
Security Groups are High Permission which can only be specified in the Admin Console of the JIVE Community. These permissions can be applied to each space, to all the blogs or all the social groups, and they can only be created by a Jive Administrator user. To retrieve these security groups ACLS the Jive Security Mapper Plug-in must be installed in your community.
Why when I perform incremental crawls, I keep getting adds and deletes for the same item?
First, check that the items in which you see this behavior are not being constantly added or deleted. If that is not the situation, probably the issue is related to a bad functioning of the Jive REST API. We have seen that in some scenarios, the Jive REST API is not being able to handle correctly the requests causing that sometimes the response comes with missing items. This will cause that the Aspire Jive connector detect these changes as adds or deletes.
For example, when we request items from People endpoint we get the following items:
- people1
- people2
- people3
- people4
- people5
At a second request for the same items, we may get:
- people1
- people2
- people4
- people5
(The connector would detect a delete of people3)
And at a third request we could get:
- people1
- people3
- people4
- people5
- people6
(The connector would detect a delete of people2 / add of people3 / add of people6)
What is the Creation Date Filter option?
If you enable this option it will let you perform crawls based on the creation date of the documents and data. This approach improves Full Crawl performance but it is only available in Jive 8 or greater.
What does the Use Progressive Retries option does?
If you enable the Progressive Retries option, the connector will let you manage how often you can retry a failed crawl. Basically, it will show you three new fields:
- Min Wait: This is the minimum amount of time the system will wait before retrying a failed crawl. This time is set in seconds.
- Increment: This is the amount of time added each time a crawl fails. If you, for instance, have set Min Wait to 10 seconds and specify a 40s Increment, the first try will take 10s, the second one 50s, the third 90s and so on. You can specify this time in seconds, minutes or as a multiplier. If the increment is set as a multiplier, it will multiply the Min Wait value by the Increment each time a crawl fails. For instance if you set Min Wait to 10s and specify a 4x increment, the first try will take 10s, the second one 40s, the third one 120s, the fourth one 480s and so on. Increment is specified by a number followed by a letter: s is for seconds, m is for minutes and x is for the multiplier increment.
- Max Wait: This is the maximum amount of time allowed by the system to make a retry. Once the wait time for a retry has exceeded this value the operation will be aborted. This time is set in minutes. For instance, if you set Min Wait to 10s, 2m increment and a Max Wait of 5 minutes, the first try will take 10s, the second one 2m 10s, the third one 4m 10s, the fourth one will abort since we would exceed the 5 minutes Max Wait with 6m 10s.
The Connection Retries field works hand in hand with Max Wait. Retry requests cannot exceed Max Wait times nor the specified Connection Retries.
What ACLs are assigned for the People?
The information of each person is public, and the connector includes all the people in a group called All Public that grants access to the people information.
Connector output
...
<acls>
<acl name="PUBLIC:ALL" scope="global" entity="group" access="allow"/>
</acls>
...
Troubleshooting
Error - No enum constant
If you see the error "No enum constant com.searchtechnologies.aspire.componetns.JiveItemType.JiveItemTypeEnum.event". JIVE allows for the inclusion of non-standard file types, a non-conventional type. This error occurs when a non-conventional type is discovered by the connector. The fix for this is specific to the non-conventional file type causing the issue. Please contact Search Technologies support for help resolving the issue.
Save your content source before creating or editing another one
Failing to save a content source before creating or editing another content source can result in an error.
ERROR [aspire]: Exception received attempting to get execute component command com.searchtechnologies.aspire.services.AspireException: Unable to find content source
Save the initial content source before creating or working on another.
Overview
Content Tools