FAQs
Specific
How get WSDL file from URL?
The WSDL can be obtained from the following URL http://example-custhelp.com/cgi-bin/interface.cfg/services/soap?wsdl=typed
This URL will always return the latest version of the WSDL.
If a previous WSDL version is needed, it can be seen with the following URL https://example-custhelp.com/cgi-bin/interface.cfg/services/soap?wsdl=typed_v(version_number)
How generate source code from WSDL URL?
- Download Axis2 from http://axis.apache.org/axis2/java/core/download.cgi
- Decompress the file.
- Open a console.
- Go to the \bin folder of the uncompressed file.
Execute the command
wsdl2java options:
-uri: WSDL location
-ns2p: Set the namespace for each package in the notation of [namespace]=[package], could change between versions of Right Now, see Right Now Getting Started (Axis2) - Creating the Ant Build File
-u: Unpack databinding classes
-uw: Switch on un-wrapping
-or: Overwrite files
General
Why does an incremental crawl last as long as a full crawl?
Some connectors perform incremental crawls based on snapshot entries, which are meant to match the exact documents that have been indexed by the connector to the search engine. On an incremental crawl, the connector fully crawls the repository the same way as a full crawl, but it only indexes the modified, new or deleted documents during that crawl.
For a discussion on crawling, see Full & Incremental Crawls.
Save your content source before creating or editing another one
Failing to save a content source before creating or editing another content source can result in an error.
ERROR [aspire]: Exception received attempting to get execute component command com.searchtechnologies.aspire.services.AspireException: Unable to find content source
Save the initial content source before creating or working on another.
My connector keeps the same status "Running" and is not doing anything
After a crawl has finished, the connector status may not be updated correctly.
To confirm this, do the following:
1. In RoboMongo, go to your connector database (like: aspire-nameOfYourConnector).
2. Open the "Status" collection and perform the following query:
db.getCollection('status').find({}).limit(1).sort({$natural:-1})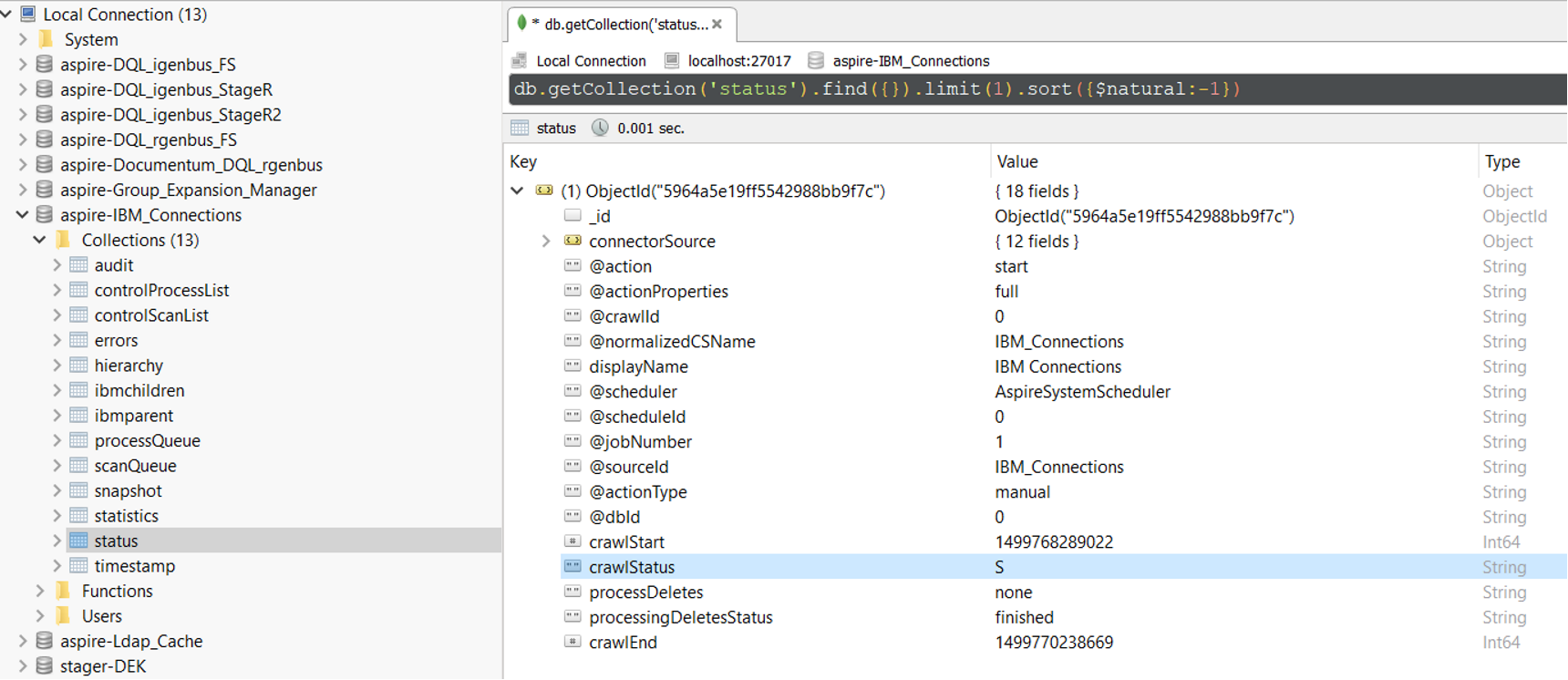
3, Edit the entry and set the status to "S" (Completed).

Note: To see the full options of "Status" values, see MongoDB Collection Status.
My connector is not providing group expansion results
Make sure your connector has a manual scheduler configured for Group Expansion.

1, Go to the Aspire debug console, and look for the respective scheduler (in the fourth table: Aspire Application Scheduler).
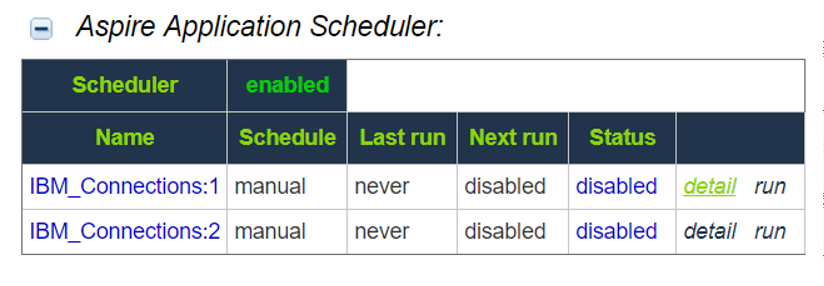
2. If you are unsure which scheduler is for Group Expansion, you can check the Schedule Detail.
- You can identify it with the value: cacheGroups

3.To run the Group Expansion process, click Run.

Troubleshooting
Problem
The connector is returning duplicated data.
Solution
Verify that multi-valued fields are not included on the Index Query.
To include them, Sub-Queries for those fields must be created.
Overview
Content Tools