Page History
2. Browse to: http://localhost:50505.
For details on using the Aspire Content Source Management page, please refer to Admin UI.


"" pulldown select Manually and pulldown pulldown in the option rearrange unselect "" checkbox

- Example
- Example
 Step 2c. Specify Workflow Information
Step 2c. Specify Workflow Information
In the "Workflow" the StageR.
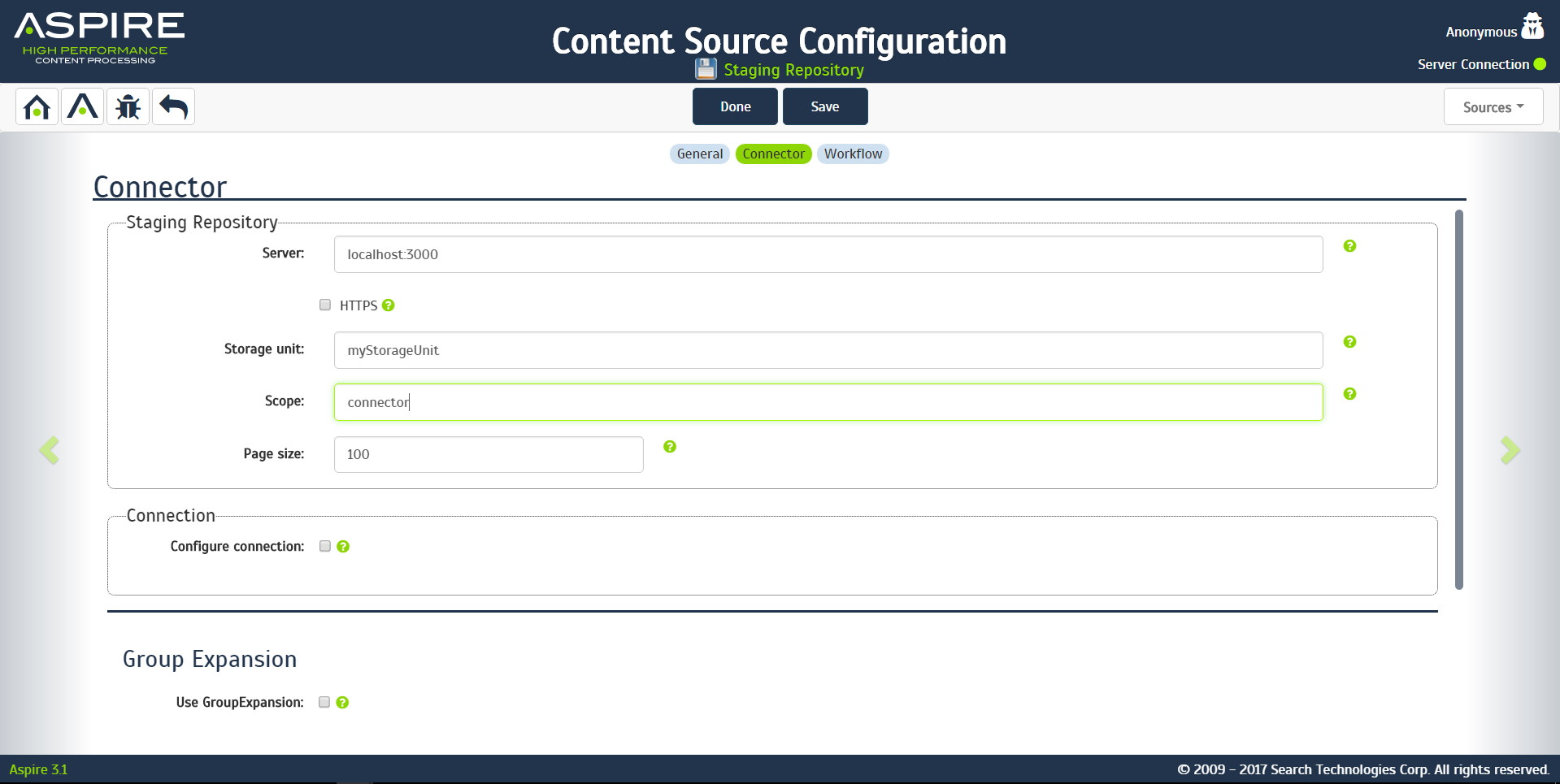
- Server
- The host and port of the server the STageR is running on
- The STageR's default port is 3000
- The host and port of the server the STageR is running on
- Use https
- Check this box if your STageR requires an https connection
- Storage Unit
- The name of the STageR storage unit you wish to crawl
- Scope
- The scope with in the STageR's storage unit you wish to crawl
- Page size
- The number of transactions to retrieve from the STageR in a single call
- Server
If required, you can also configure the connection to the STageR. Check the configure connection check box to allow you to configure:
- Connection timeout
- Period to attempt to connect to the STageR for before timing out
- Read timeout
- Period to attempt to read from the STageR for before timing out
- Period to attempt to read from the STageR for before timing out
- Retries
- The number of retries that will be attempted when a connection or read timeout occurs before the STageR reports an error
- Retry delay
- The period to wait after a failure before retrying the operation
- Retry policy
- Fixed
- The same delay will apply on each retry
- Increasing
- The delay will be the attempt number multiplied by a fixed value
- eg for a value of 2, the delay would be 2, 4, 6, 8 etc
- A maximum delay can be specified
- The delay will be the attempt number multiplied by a fixed value
- Cumulative
- The delay will be increased by a multiple on each attempt
- eg for a delay of 3 and a multiplier of 2, the delay would be 3, 3x2, 3x2x2, 3x2x2x2 (3, 6, 12, 24) etc
- A maximum delay can be specified
- The delay will be increased by a multiple on each attempt
- Fixed
- Connection timeout

- page.
- page.
Overview
Content Tools